PHI Labeling Process
Introduction
In this report, we outline the methodology used to create a labeled dataset with annotated PHI from clinical notes. Specifically, we describe the process for sampling clinical notes and performing annotations. This process was designed to achieve the following objectives:
- Ensuring demographic representation across diverse patient populations
- Maintaining consistency in annotation across multiple annotators
- Balancing efficiency with quality in the annotation process
- Managing the resource-intensive nature of medical text annotation
Figure 1 provides an overview of the labeling process.
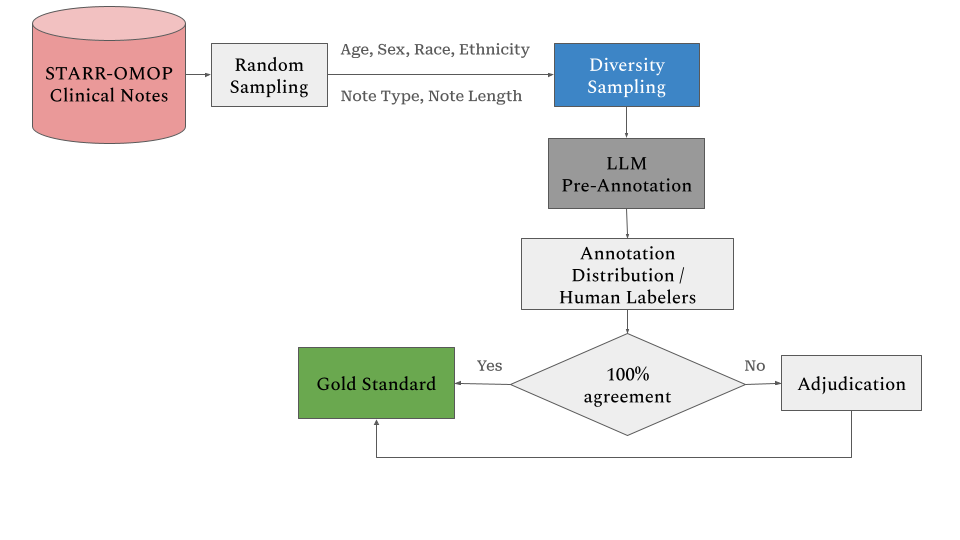
Data Sampling Methodology
The data sampling was performed in two steps. First, we conducted a random sampling across the entire set of notes. Then, we applied diversity sampling using a set cover algorithm. The details of these procedures are outlined below.
Note Characteristics Analysis
The sampling process incorporates textual characteristics to ensure diversity in content:
- Note titles are categorized to represent different types of clinical documentation.
- Note length distribution is analyzed using a binning approach:
- Calculation of the median length per note title
- Computation of the median of medians
- Selection of notes between the 25th and 75th percentiles
- Quantization into four distinct bins for balanced representation
- Calculation of the median length per note title
Set Cover Algorithm Implementation
To optimize sampling while maintaining representation across all demographic and textual characteristics, we implemented a modified set cover algorithm:
- Initial random sampling of 1M notes to create a computationally manageable subset
- Application of a set cover algorithm to ensure representation across all defined partitions
- Optimization for maximum coverage with minimal redundancy
Annotation Guidelines Development
Guideline Structure
Comprehensive annotation guidelines were developed through an iterative process. These guidelines include:
- Clear definitions of annotation targets
- Explicit inclusion and exclusion criteria
- Representative examples
- Decision trees for ambiguous cases
- Standard operating procedures for the annotation workflow
The labeling guidelines can be found here.
Guideline Validation
The guidelines underwent multiple validation cycles, including:
- Pilot testing with experienced annotators
- Refinement based on inter-annotator agreement analysis
- Integration of edge cases identified during initial annotation phases
Pre-labeling and Annotation Distribution Process
LLM Pre-Annotation Implementation
The pre-labeling process utilized GPT-4 via Azure’s API (version 2023-05-15), incorporating:
- Prompt engineering optimized using the I2B2 dataset
- Integration of annotation guidelines into prompt design
- Systematic validation of pre-labeled outputs
Annotation Distribution
Notes were assigned following a structured protocol:
- Random assignment to ensure unbiased distribution
- Dual annotator requirement for each note to enable quality assessment
- Tracking system implementation to monitor annotation progress
- Regular checkpoints for interim quality assessments
Quality Control Framework
The quality assessment framework employs a bilateral F1 measure approach:
- Primary F1 calculation:
- Annotator A’s labels serve as the ground truth against Annotator B’s annotations
- Annotator B’s labels serve as the ground truth against Annotator A’s annotations
- The final F1 score is computed as the arithmetic mean of both directions
- Annotator A’s labels serve as the ground truth against Annotator B’s annotations
Adjudication Process
All clinical notes without 100% agreement across annotated spans undergo an adjudication process. Experienced annotators review and resolve disagreements to ensure annotation quality. Only the notes with 100% agreement or adjudicated notes are used as gold standard.