Data Evolution Overview
This page provides an overview of the VISTA Oncology Data Lake’s evolution across multiple releases, showcasing the progressive expansion and maturation of our comprehensive cancer research platform. The data lake has grown substantially from February 2025 through May 2026, with significant increases in patient coverage, data source integration, and analytical capabilities, including the addition of whole slide imaging and detailed genomic variant data.
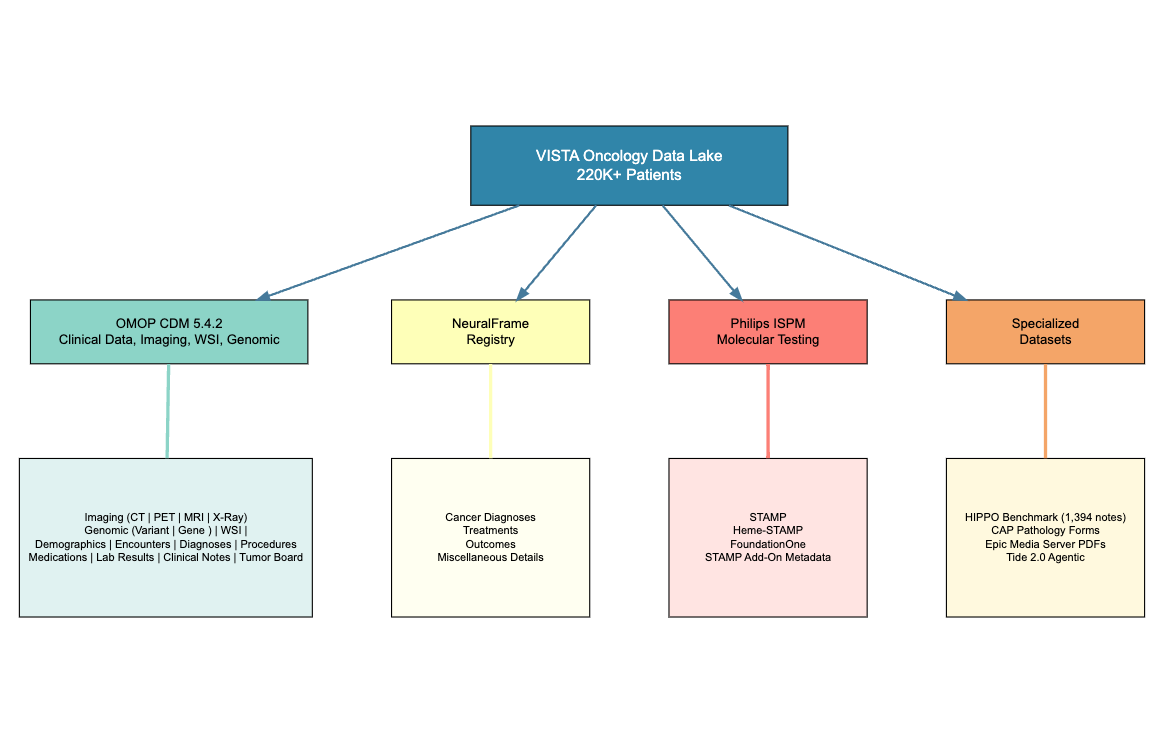
Release Overview
The VISTA Oncology Data Lake represents a multi-institutional effort to create a comprehensive, longitudinal cancer research resource. Through systematic data releases from February 2025 through May 2026, the platform has grown from approximately 200,000 to over 220,000 patients, progressively integrating clinical OMOP data, NeuralFrame registry records, medical imaging, and molecular testing from Philips ISPM. This evolution includes specialized datasets such as the HIPPO benchmark corpus and CAP pathology forms, alongside the development of disease-specific sub-cohorts for focused research applications. The November 2025 release introduces a major OMOP 5.4 upgrade with modernized vocabularies and enhanced ETL pipelines. The February 2026 release adds whole slide imaging and a custom variant occurrence table for granular genomic data. The May 2026 release expands WSI coverage and introduces the OMOP episode table for treatment plan analysis, along with Heme-STAMP variants, marking continued advancements in multi-modal data integration and research capabilities.
February 2025 - Foundation Release
The inaugural February 2025 release established the core OMOP 5.3.1 CDM foundation of our data lake, providing:
- Core OMOP Dataset: Comprehensive patient demographics, encounters, diagnoses, and procedures following OMOP CDM 5.3.1 standards
- Clinical Infrastructure: Essential clinical data including medications (RxNorm), laboratory results (LOINC), and procedure codes (CPT)
- NeuralFrame Diagnoses: Initial integration of Stanford Cancer Registry diagnosis data
- Quality Framework: Initial data validation and PHI scrubbing processes to ensure research readiness
- Patient Base: Approximately 200,000+ oncology patients forming the foundational cohort
This release prioritized data quality and standardization, establishing the structural foundation for subsequent data integration efforts.
May 2025 - Integration Expansion
The May 2025 release marked a significant evolution with the integration of multiple specialized data sources:
- NeuralFrame Integration: Addition of Stanford Cancer Registry data, providing comprehensive cancer case information including miscellaneous, treatments, and outcomes
- Imaging Data: Integration of OMOP image occurrence data, linking patients to their diagnostic imaging studies
- Philips ISPM: Introduction of molecular testing data including STAMP, Heme-STAMP, and FoundationOne results
- Enhanced Coverage: Substantial increase in patient coverage across multiple data domains
This release transformed the data lake from a primarily clinical dataset to a multi-modal research platform supporting translational cancer research.
August 2025 - Depth and Specialization
The August 2025 release focused on increasing data depth and developing specialized research capabilities:
- STAMP Add-On Dataset: Integrated detailed genomic testing metadata including assay types (STAMP, Heme-STAMP), pipeline versions, and test identifiers for comprehensive molecular profiling analysis
- HIPPO Benchmark: Added 1,394 expert-annotated clinical notes corpus for PHI identification and de-identification methodology validation
- Lung Resection CAP Forms: Introduced fully identified structured pathology reports combining standardized College of American Pathologists (CAP) templates with unstructured clinical information
- Epic Media Server Documents: Integrated all PDF documents from third-party providers accessible via EPIC Media/Lab tabs and Mulesoft API
- Enhanced Metadata: Expanded technical documentation including DICOM dictionary, STAMP gene panels, and genomic BED files
This release established the data lake as a comprehensive resource for both population-level and detailed clinical research, while adding critical benchmarking datasets for data quality and PHI scrubbing validation.
November 2025 - Advanced Analytics
The November 2025 release represents a major technical advancement with comprehensive OMOP upgrade and enhanced data capabilities:
- OMOP 5.3 to 5.4 Upgrade: Migrated to OMOP CDM version 5.4.2 with new tables, enhanced field linking capabilities, and updated naming conventions for improved data interoperability. This includes the addition of several new tables (not yet populated) as well as additional fields for linking between tables, along with several other minor name changes. A full description of the CDM changes can be found here.
- Vocabulary Modernization: Updated from January 2023 to August 2025 OHDSI vocabulary, incorporating 2.5 years of concept mappings, domain changes, and standardization improvements
- Pipeline Redesign: Overhauled ETL processes with standardized filtering (events from 2000+, flexible visit requirements) and enhanced JSON-formatted source value fields for improved data traceability
- Genomic Tests Expansion: Expanded Stanford test types coverage including comprehensive FoundationOne molecular profiling results
- Agentic Tide Integration: Advanced analytics capabilities for automated data processing and analysis
This release modernizes the technical infrastructure while maintaining backward compatibility, positioning the data lake for next-generation research applications and enhanced analytical capabilities.
February 2026 - WSI and Genomic Expansion
The February 2026 release expands the data lake with whole slide imaging and detailed genomic variant data:
- Whole Slide Imaging (WSI): Integration of manually scanned, deidentified histopathology slides stored as TIFF image files with corresponding JSON metadata. Dataset includes only slides with order_proc_ids that can be linked to Epic Clarity to ensure appropriate patient cohort inclusion and data quality
- Variant Occurrence Table: Custom STARR-OMOP table containing detailed genetic variant information from genomic testing. Currently includes variants from STAMP (Stanford Actionable Mutation Panel for Solid Tumors) tests processed through Epic Genomics Suite starting August 2025, with plans to expand to additional test types and variant classes in future releases
This release significantly expands pathology imaging capabilities and provides granular genomic variant data for translational research applications.
May 2026 - WSI, Episode Table, and Heme-STAMP Variants
The May 2026 release further expands the data lake with additional whole slide imaging data, the introduction of an episode table, and expanded genomic variant coverage:
- Whole Slide Imaging Expansion: Continued integration of manually scanned, deidentified histopathology slides with expanded coverage and enriched metadata including new fields from Clarity (
specimen_received_date,spec_task_listarray with stainer information) and from WSI metadata (brand,scanner,microns_per_pixel) - Episode Table Introduction: Addition of a custom STARR-OMOP episode table capturing clinical episodes representing treatment plans for patients in the oncology cohort, enabling analysis of care trajectories and treatment patterns
- Heme-STAMP Variants: Expanded the variant occurrence table to include Heme-STAMP test results alongside existing STAMP variants
Release Summary Table
The following table provides a comprehensive overview of data and schema changes across all releases:
Patient Identifier Keys by Dataset
The following table shows the key identifier fields used in each dataset across releases, reflecting the evolution toward standardized patient linkage:
Key Identifier Notes:
- person_id: OMOP standard identifier used across clinical tables for patient linkage
- person_source_value: Source system identifier in OMOP tables that joins with stanford_patient_uid for cross-dataset linkage
- stanford_patient_uid: Stanford-specific unique patient identifier used in NeuralFrame and Philips ISPM datasets which is concatenation of MRN and DOB
- MRN, DOB: Medical Record Number and Date of Birth combination (used in February 2025 before standardization) The transition from MRN/DOB combinations to standardized identifiers (person_id, stanford_patient_uid) in May 2025 significantly improved cross-dataset linkage capabilities and simplified cohort construction workflows.
Additional Linkage Fields:
Image Occurrence table also includes note_id, visit_occurrence_id, and accession_number for linking to clinical notes, visits, and imaging studies
Philips ISPM includes accession_number for linking genomic test results to specific clinical specimens and visits
Whole Slide Imaging includes accession_number and note_id for linking histopathology slides to clinical notes and specimens
Variant Occurrence includes accession_number for linking genomic variants to specific clinical specimens and visits, visit_occurrence_id for linking to clinical visits, and procedure_occurrence_id for linking to specific procedures associated with genomic testing
Episode includes person_id for linking clinical episodes to patients in the oncology cohort
†November 2025 OMOP 5.4 Update: In the November 2025 release, person_source_value is JSON-formatted. To join with stanford_patient_uid, extract the field using: JSON_VALUE(person_source_value, '$.stanford_patient_uid')
Multi-Release Statistical Overview
For detailed statistical analysis and interactive visualizations of data coverage trends across all releases, see the Data Coverage Trends page. For PHI Scrubbed data coverage trends, see the PHI Scrubbed Data Coverage Trends page.
For each data release (February 2025 to May 2026), we examine:
- Demographic characteristics (cohort size, age distribution, gender, race)
- Data source coverage across integrated systems (NeuralFrame, Philips ISPM, Imaging, Tumor Board)
- OMOP clinical data availability (diagnoses, procedures, medications, lab results, clinical notes)
- Tumor board and thoracic sub-cohort populations with multi-modal data integration
- Imaging modality coverage and metadata diversity
- Molecular testing patterns and genomic profiling distributions